Topic 4. Linear Classification and Regression#
Part 3. An Illustrative Example of Logistic Regression Regularization#

Author: Yury Kashnitsky. Translated and edited by Christina Butsko, Nerses Bagiyan, Yulia Klimushina, and Yuanyuan Pao. This material is subject to the terms and conditions of the Creative Commons CC BY-NC-SA 4.0 license. Free use is permitted for any non-commercial purpose.
Article outline#
In the first article, we demonstrated how polynomial features allow linear models to build nonlinear separating surfaces. Let’s now show this visually.
Let’s see how regularization affects the quality of classification on a dataset on microchip testing from Andrew Ng’s course on machine learning. We will use logistic regression with polynomial features and vary the regularization parameter \(C\). First, we will see how regularization affects the separating border of the classifier and intuitively recognize under- and overfitting. Then, we will choose the regularization parameter to be numerically close to the optimal value via (cross-validation) and (GridSearch).
# we don't like warnings
# you can comment the following 2 lines if you'd like to
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
#sharper plots
%config InlineBackend.figure_format = 'retina'
from sklearn.linear_model import LogisticRegression, LogisticRegressionCV
from sklearn.model_selection import (GridSearchCV, StratifiedKFold,
cross_val_score)
from sklearn.preprocessing import PolynomialFeatures
Let’s load the data using read_csv from the pandas library. In this dataset on 118 microchips (objects), there are results for two tests of quality control (two numerical variables) and information whether the microchip went into production. Variables are already centered, meaning that the column values have had their own mean values subtracted. Thus, the “average” microchip corresponds to a zero value in the test results.
# for Jupyter-book, we copy data from GitHub, locally, to save Internet traffic,
# you can specify the data/ folder from the root of your cloned
# https://github.com/Yorko/mlcourse.ai repo, to save Internet traffic
DATA_PATH = "https://raw.githubusercontent.com/Yorko/mlcourse.ai/main/data/"
# loading data
data = pd.read_csv(
DATA_PATH + "microchip_tests.txt",
header=None,
names=("test1", "test2", "released")
)
# getting some info about dataframe
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 118 entries, 0 to 117
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 test1 118 non-null float64
1 test2 118 non-null float64
2 released 118 non-null int64
dtypes: float64(2), int64(1)
memory usage: 2.9 KB
Let’s inspect at the first and last 5 lines.
data.head(5)
| test1 | test2 | released | |
|---|---|---|---|
| 0 | 0.051267 | 0.69956 | 1 |
| 1 | -0.092742 | 0.68494 | 1 |
| 2 | -0.213710 | 0.69225 | 1 |
| 3 | -0.375000 | 0.50219 | 1 |
| 4 | -0.513250 | 0.46564 | 1 |
data.tail(5)
| test1 | test2 | released | |
|---|---|---|---|
| 113 | -0.720620 | 0.538740 | 0 |
| 114 | -0.593890 | 0.494880 | 0 |
| 115 | -0.484450 | 0.999270 | 0 |
| 116 | -0.006336 | 0.999270 | 0 |
| 117 | 0.632650 | -0.030612 | 0 |
Now we should save the training set and the target class labels in separate NumPy arrays.
X = data.iloc[:, :2].values
y = data.iloc[:, 2].values
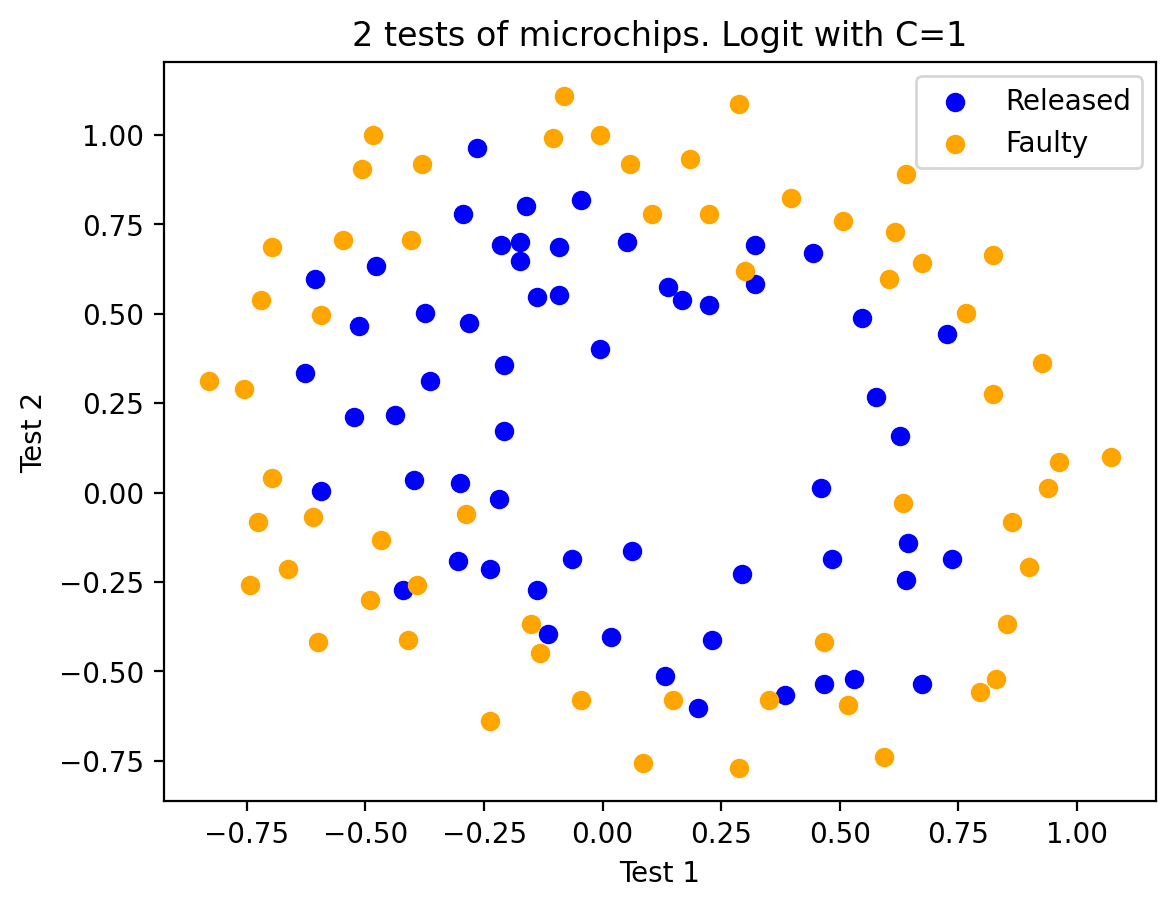
As an intermediate step, we can plot the data. Orange points correspond to defective chips, blue to normal ones.
plt.scatter(X[y == 1, 0], X[y == 1, 1], c="blue", label="Released")
plt.scatter(X[y == 0, 0], X[y == 0, 1], c="orange", label="Faulty")
plt.xlabel("Test 1")
plt.ylabel("Test 2")
plt.title("2 tests of microchips. Logit with C=1")
plt.legend();
Let’s define a function to display the separating curve of the classifier.
def plot_boundary(clf, X, y, grid_step=0.01, poly_featurizer=None):
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(
np.arange(x_min, x_max, grid_step), np.arange(y_min, y_max, grid_step)
)
# to every point from [x_min, m_max]x[y_min, y_max]
# we put in correspondence its own color
Z = clf.predict(poly_featurizer.transform(np.c_[xx.ravel(), yy.ravel()]))
Z = Z.reshape(xx.shape)
plt.contour(xx, yy, Z, cmap=plt.cm.Paired)
We define the following polynomial features of degree \(d\) for two variables \(x_1\) and \(x_2\):
For example, for \(d=3\), this will be the following features:
Drawing a Pythagorean Triangle would show how many of these features there will be for \(d=4,5...\) and so on. The number of such features is exponentially large, and it can be costly to build polynomial features of large degree (e.g \(d=10\)) for 100 variables. More importantly, it’s not needed.
We will use sklearn’s implementation of logistic regression. So, we create an object that will add polynomial features up to degree 7 to matrix \(X\).
poly = PolynomialFeatures(degree=7)
X_poly = poly.fit_transform(X)
X_poly.shape
(118, 36)
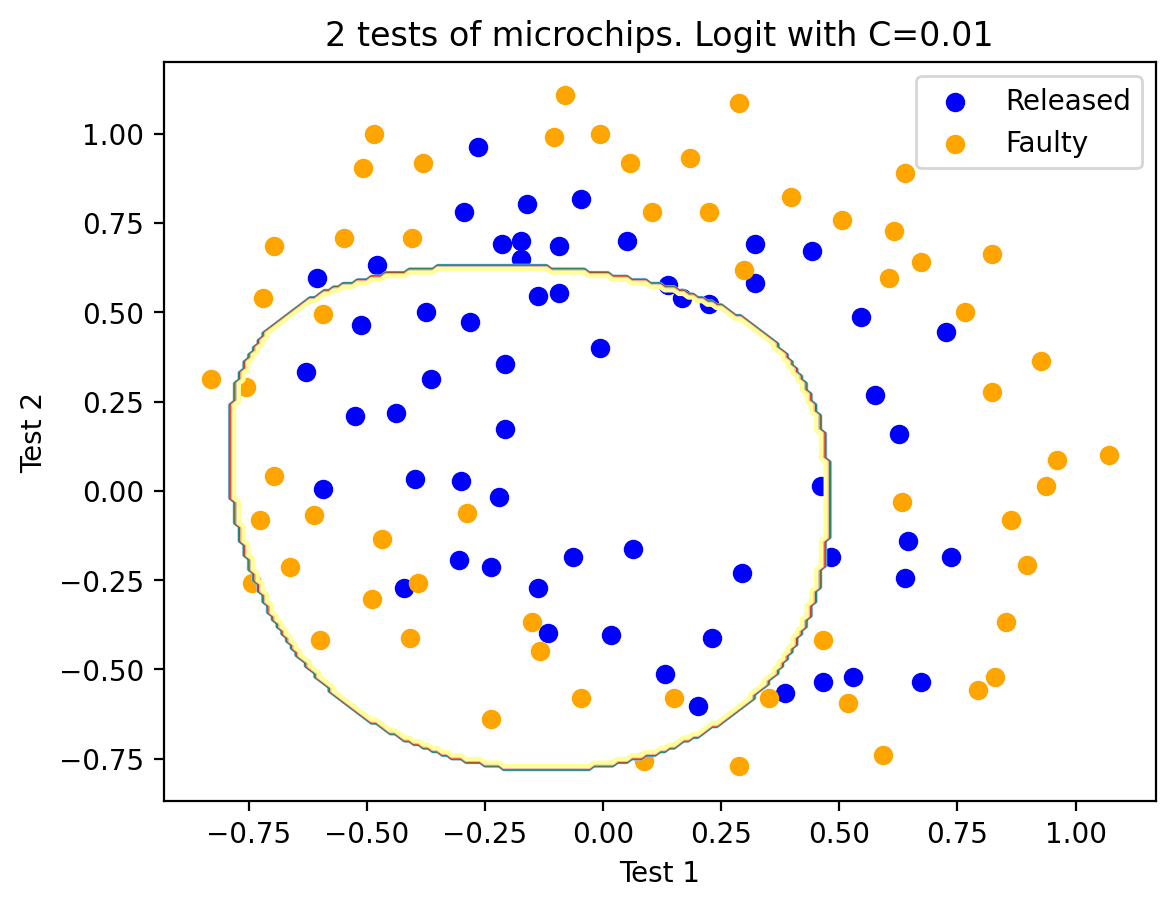
Let’s train logistic regression with regularization parameter \(C = 10^{-2}\).
C = 1e-2
logit = LogisticRegression(C=C, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=0.01, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c="blue", label="Released")
plt.scatter(X[y == 0, 0], X[y == 0, 1], c="orange", label="Faulty")
plt.xlabel("Test 1")
plt.ylabel("Test 2")
plt.title("2 tests of microchips. Logit with C=%s" % C)
plt.legend()
print("Accuracy on training set:", round(logit.score(X_poly, y), 3))
Accuracy on training set: 0.627
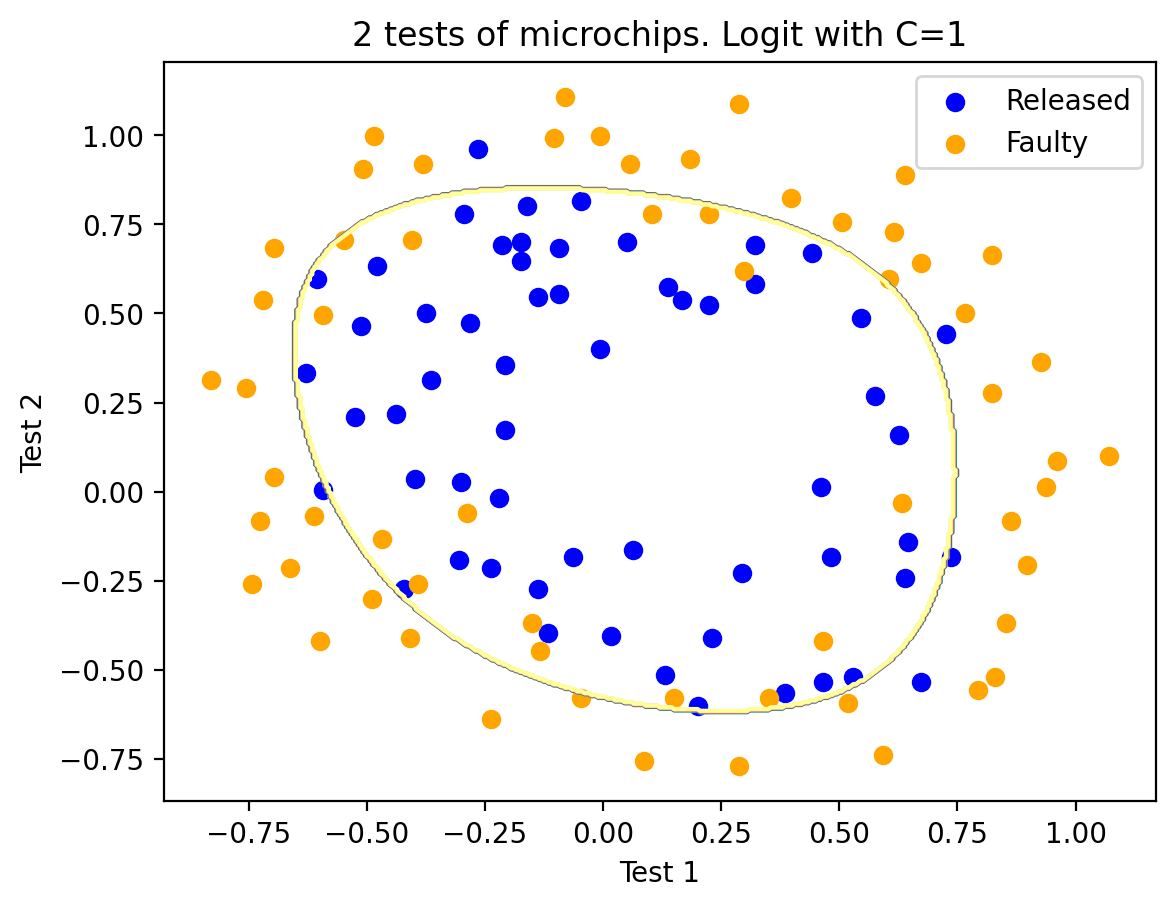
We could now try increasing \(C\) to 1. In doing this, we weaken regularization, and the solution can now have greater values (in absolute value) of model weights than previously. Now the accuracy of the classifier on the training set improves to 0.831.
C = 1
logit = LogisticRegression(C=C, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=0.005, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c="blue", label="Released")
plt.scatter(X[y == 0, 0], X[y == 0, 1], c="orange", label="Faulty")
plt.xlabel("Test 1")
plt.ylabel("Test 2")
plt.title("2 tests of microchips. Logit with C=%s" % C)
plt.legend()
print("Accuracy on training set:", round(logit.score(X_poly, y), 3))
Accuracy on training set: 0.831
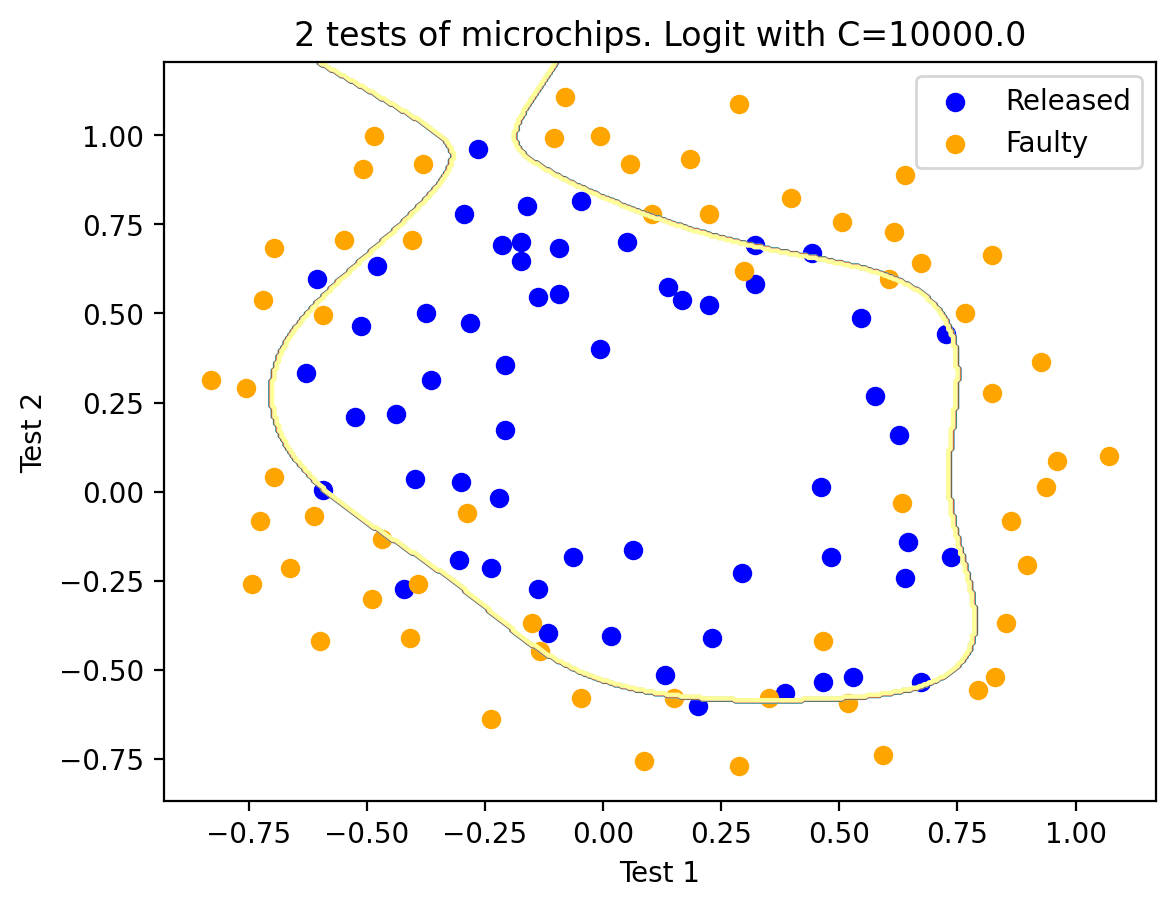
Then, why don’t we increase \(C\) even more - up to 10,000? Now, regularization is clearly not strong enough, and we see overfitting. Note that, with \(C\)=1 and a “smooth” boundary, the share of correct answers on the training set is not much lower than here. But one can easily imagine how our second model will work much better on new data.
C = 1e4
logit = LogisticRegression(C=C, random_state=17)
logit.fit(X_poly, y)
plot_boundary(logit, X, y, grid_step=0.005, poly_featurizer=poly)
plt.scatter(X[y == 1, 0], X[y == 1, 1], c="blue", label="Released")
plt.scatter(X[y == 0, 0], X[y == 0, 1], c="orange", label="Faulty")
plt.xlabel("Test 1")
plt.ylabel("Test 2")
plt.title("2 tests of microchips. Logit with C=%s" % C)
plt.legend()
print("Accuracy on training set:", round(logit.score(X_poly, y), 3))
Accuracy on training set: 0.873
To discuss the results, let’s rewrite the function that is optimized in logistic regression with the form:
where
\(\mathcal{L}\) is the logistic loss function summed over the entire dataset
\(C\) is the reverse regularization coefficient (the very same \(C\) from
sklearn’s implementation ofLogisticRegression)
Subtotals:
the larger the parameter \(C\), the more complex the relationships in the data that the model can recover (intuitively \(C\) corresponds to the “complexity” of the model - model capacity)
if regularization is too strong i.e. the values of \(C\) are small, the solution to the problem of minimizing the logistic loss function may be the one where many of the weights are too small or zeroed. The model is also not sufficiently “penalized” for errors (i.e. in the function \(J\), the sum of the squares of the weights “outweighs”, and the error \(\mathcal{L}\) can be relatively large). In this case, the model will underfit as we saw in our first case.
on the contrary, if regularization is too weak i.e. the values of \(C\) are large, a vector \(w\) with high absolute value components can become the solution to the optimization problem. In this case, \(\mathcal{L}\) has a greater contribution to the optimized functional \(J\). Loosely speaking, the model is too “afraid” to be mistaken on the objects from the training set and will therefore overfit as we saw in the third case.
logistic regression will not “understand” (or “learn”) what value of \(C\) to choose as it does with the weights \(w\). That is to say, it can not be determined by solving the optimization problem in logistic regression. We have seen a similar situation before – a decision tree can not “learn” what depth limit to choose during the training process. Therefore, \(C\) is a model hyperparameter that is tuned on cross-validation; so is the max_depth in a tree.
Regularization parameter tuning
Using this example, let’s identify the optimal value of the regularization parameter \(C\). This can be done using LogisticRegressionCV - a grid search of parameters followed by cross-validation. This class is designed specifically for logistic regression (effective algorithms with well-known search parameters). For an arbitrary model, use GridSearchCV, RandomizedSearchCV, or special algorithms for hyperparameter optimization such as the one implemented in hyperopt.
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=17)
c_values = np.logspace(-2, 3, 500)
logit_searcher = LogisticRegressionCV(Cs=c_values, cv=skf, n_jobs=-1)
logit_searcher.fit(X_poly, y);
logit_searcher.C_
array([154.30384692])
To see how the quality of the model (percentage of correct responses on the training and validation sets) varies with the hyperparameter \(C\), we can plot the graph.
plt.plot(c_values, np.mean(logit_searcher.scores_[1], axis=0))
plt.xlabel("C")
plt.ylabel("Mean CV-accuracy");
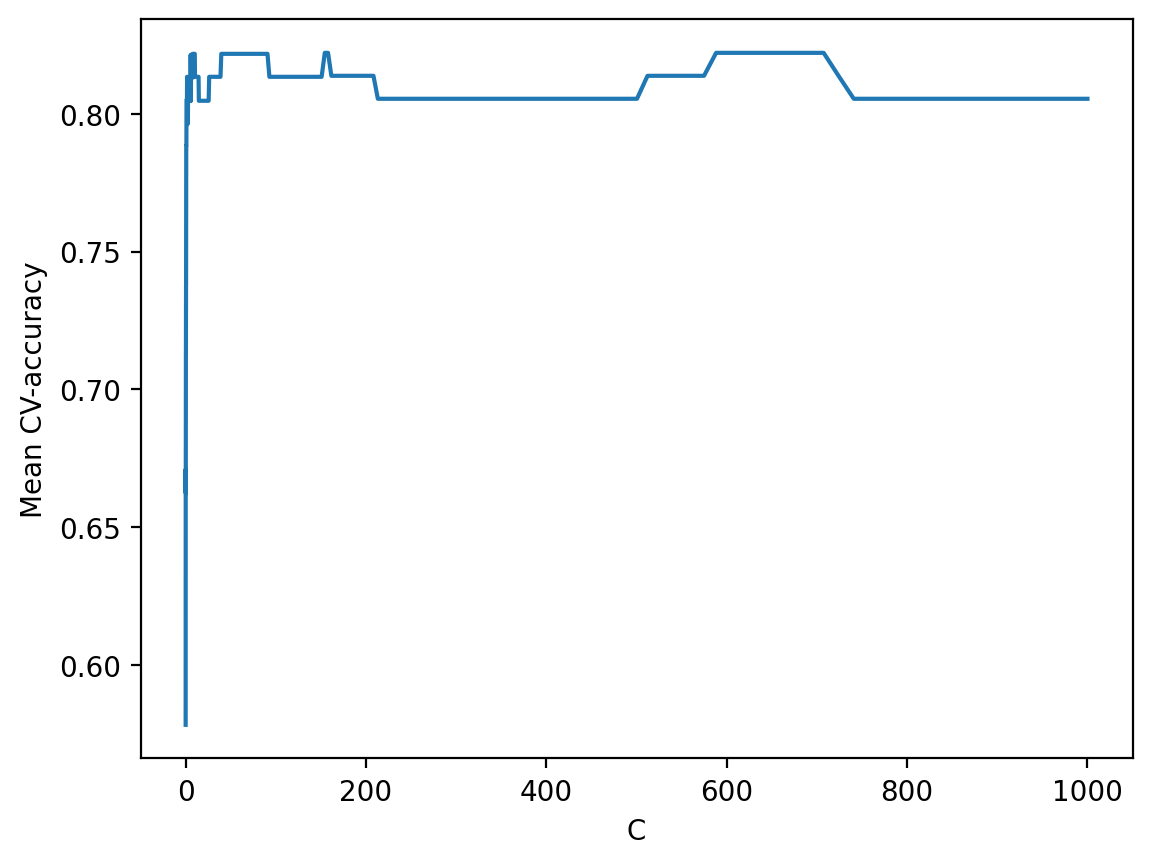
Finally, select the area with the “best” values of \(C\).
plt.plot(c_values, np.mean(logit_searcher.scores_[1], axis=0))
plt.xlabel("C")
plt.ylabel("Mean CV-accuracy")
plt.xlim((0, 10));
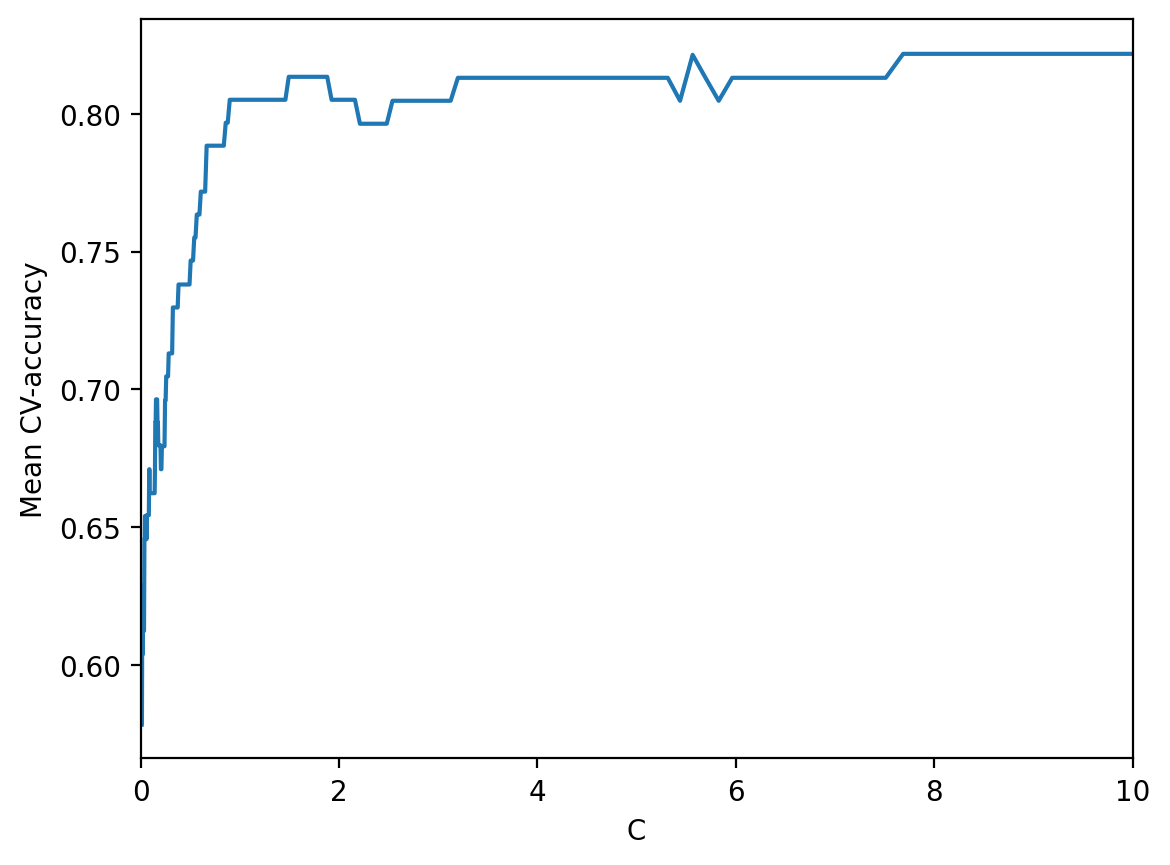
Recall that these curves are called validation curves. Previously, we built them manually, but sklearn has special methods to construct these that we will use going forward.
Useful resources#
Main course site, course repo, and YouTube channel
Medium “story” based on this notebook
Course materials as a Kaggle Dataset
If you read Russian: an article on Habrahabr with ~ the same material. And a lecture on YouTube
A nice and concise overview of linear models is given in the book “Deep Learning” (I. Goodfellow, Y. Bengio, and A. Courville).
Linear models are covered practically in every ML book. We recommend “Pattern Recognition and Machine Learning” (C. Bishop) and “Machine Learning: A Probabilistic Perspective” (K. Murphy).
If you prefer a thorough overview of linear models from a statistician’s viewpoint, then look at “The elements of statistical learning” (T. Hastie, R. Tibshirani, and J. Friedman).
The book “Machine Learning in Action” (P. Harrington) will walk you through implementations of classic ML algorithms in pure Python.
Scikit-learn library. These guys work hard on writing really clear documentation.
Scipy 2017 scikit-learn tutorial by Alex Gramfort and Andreas Mueller.
One more ML course with very good materials.
Implementations of many ML algorithms. Search for linear regression and logistic regression.