Topic 4. Linear Classification and Regression#
Part 4. When Logistic Regression Is Good and When It Is Not#

Author: Yury Kashnitsky. Translated and edited by Christina Butsko, Nerses Bagiyan, Yulia Klimushina, and Yuanyuan Pao. This material is subject to the terms and conditions of the Creative Commons CC BY-NC-SA 4.0 license. Free use is permitted for any non-commercial purpose.
Article outline#
1. Analysis of IMDB movie reviews#
Now for a little practice! We want to solve the problem of binary classification of IMDB movie reviews. We have a training set with marked reviews, 12500 reviews marked as good, another 12500 bad. Here, it’s not easy to get started with machine learning right away because we don’t have the matrix \(X\); we need to prepare it. We will use a simple approach: the bag of words model. Features of the review will be represented by indicators of the presence of each word from the whole corpus in this review. The corpus is the set of all user reviews. The idea is illustrated by the picture below

import os
import numpy as np
import matplotlib.pyplot as plt
#sharper plots
%config InlineBackend.figure_format = 'retina'
from sklearn.datasets import load_files
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LogisticRegression
To get started, we automatically download the dataset from here and unarchive it along with the rest of the datasets in the data folder. The dataset is briefly described here. There are 12.5k good and 12.5k bad reviews in the test and training sets.
import tarfile
from io import BytesIO
import requests
url = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
def load_imdb_dataset(extract_path, overwrite=False):
# check if existed already
if (
os.path.isfile(os.path.join(extract_path, "aclImdb", "README"))
and not overwrite
):
print("IMDB dataset is already in place.")
return
print("Downloading the dataset from: ", url)
response = requests.get(url)
tar = tarfile.open(mode="r:gz", fileobj=BytesIO(response.content))
data = tar.extractall(extract_path)
# for Jupyter-book, we copy data from GitHub, locally, to save Internet traffic,
# you can specify the data/ folder from the root of your cloned
# https://github.com/Yorko/mlcourse.ai repo, to save Internet traffic
DATA_PATH = "../../_static/data/"
load_imdb_dataset(extract_path=DATA_PATH)
IMDB dataset is already in place.
# change if you have it in alternative location
PATH_TO_IMDB = DATA_PATH + "aclImdb"
reviews_train = load_files(
os.path.join(PATH_TO_IMDB, "train"), categories=["pos", "neg"]
)
text_train, y_train = reviews_train.data, reviews_train.target
reviews_test = load_files(os.path.join(PATH_TO_IMDB, "test"), categories=["pos", "neg"])
text_test, y_test = reviews_test.data, reviews_test.target
print("Number of documents in training data: %d" % len(text_train))
print(np.bincount(y_train))
print("Number of documents in test data: %d" % len(text_test))
print(np.bincount(y_test))
Number of documents in training data: 25000
[12500 12500]
Number of documents in test data: 25000
[12500 12500]
Here are a few examples of the reviews.
print(text_train[1])
b'Words can\'t describe how bad this movie is. I can\'t explain it by writing only. You have too see it for yourself to get at grip of how horrible a movie really can be. Not that I recommend you to do that. There are so many clich\xc3\xa9s, mistakes (and all other negative things you can imagine) here that will just make you cry. To start with the technical first, there are a LOT of mistakes regarding the airplane. I won\'t list them here, but just mention the coloring of the plane. They didn\'t even manage to show an airliner in the colors of a fictional airline, but instead used a 747 painted in the original Boeing livery. Very bad. The plot is stupid and has been done many times before, only much, much better. There are so many ridiculous moments here that i lost count of it really early. Also, I was on the bad guys\' side all the time in the movie, because the good guys were so stupid. "Executive Decision" should without a doubt be you\'re choice over this one, even the "Turbulence"-movies are better. In fact, every other movie in the world is better than this one.'
y_train[1] # bad review
np.int64(0)
text_train[2]
b'Everyone plays their part pretty well in this "little nice movie". Belushi gets the chance to live part of his life differently, but ends up realizing that what he had was going to be just as good or maybe even better. The movie shows us that we ought to take advantage of the opportunities we have, not the ones we do not or cannot have. If U can get this movie on video for around $10, it\xc2\xb4d be an investment!'
y_train[2] # good review
np.int64(1)
# import pickle
# with open('../../data/imdb_text_train.pkl', 'wb') as f:
# pickle.dump(text_train, f)
# with open('../../data/imdb_text_test.pkl', 'wb') as f:
# pickle.dump(text_test, f)
# with open('../../data/imdb_target_train.pkl', 'wb') as f:
# pickle.dump(y_train, f)
# with open('../../data/imdb_target_test.pkl', 'wb') as f:
# pickle.dump(y_test, f)
2. A Simple Word Count#
First, we will create a dictionary of all the words using CountVectorizer
cv = CountVectorizer()
cv.fit(text_train)
len(cv.vocabulary_)
74849
If you look at the examples of “words” (let’s call them tokens), you can see that we have omitted many of the important steps in text processing (automatic text processing can itself be a completely separate series of articles).
print(cv.get_feature_names_out()[:50])
print(cv.get_feature_names_out()[50000:50050])
['00' '000' '0000000000001' '00001' '00015' '000s' '001' '003830' '006'
'007' '0079' '0080' '0083' '0093638' '00am' '00pm' '00s' '01' '01pm' '02'
'020410' '029' '03' '04' '041' '05' '050' '06' '06th' '07' '08' '087'
'089' '08th' '09' '0f' '0ne' '0r' '0s' '10' '100' '1000' '1000000'
'10000000000000' '1000lb' '1000s' '1001' '100b' '100k' '100m']
['pincher' 'pinchers' 'pinches' 'pinching' 'pinchot' 'pinciotti' 'pine'
'pineal' 'pineapple' 'pineapples' 'pines' 'pinet' 'pinetrees' 'pineyro'
'pinfall' 'pinfold' 'ping' 'pingo' 'pinhead' 'pinheads' 'pinho' 'pining'
'pinjar' 'pink' 'pinkerton' 'pinkett' 'pinkie' 'pinkins' 'pinkish'
'pinko' 'pinks' 'pinku' 'pinkus' 'pinky' 'pinnacle' 'pinnacles' 'pinned'
'pinning' 'pinnings' 'pinnochio' 'pinnocioesque' 'pino' 'pinocchio'
'pinochet' 'pinochets' 'pinoy' 'pinpoint' 'pinpoints' 'pins' 'pinsent']
Secondly, we are encoding the sentences from the training set texts with the indices of the words. We’ll use the sparse format.
X_train = cv.transform(text_train)
X_train
<Compressed Sparse Row sparse matrix of dtype 'int64'
with 3445861 stored elements and shape (25000, 74849)>
Let’s see how our transformation worked
print(text_train[19726])
b'This movie is terrible but it has some good effects.'
X_train[19726].nonzero()[1]
array([ 9881, 21020, 28068, 29999, 34585, 34683, 44147, 61617, 66150,
66562], dtype=int32)
X_train[19726].nonzero()
(array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=int32),
array([ 9881, 21020, 28068, 29999, 34585, 34683, 44147, 61617, 66150,
66562], dtype=int32))
Third, we will apply the same operations to the test set
X_test = cv.transform(text_test)
The next step is to train Logistic Regression.
%%time
logit = LogisticRegression(solver="lbfgs", n_jobs=-1, random_state=7, max_iter=500)
logit.fit(X_train, y_train)
CPU times: user 27.5 ms, sys: 141 ms, total: 169 ms
Wall time: 6.05 s
LogisticRegression(max_iter=500, n_jobs=-1, random_state=7)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LogisticRegression(max_iter=500, n_jobs=-1, random_state=7)
Let’s look at accuracy on both the training and the test sets.
round(logit.score(X_train, y_train), 3), round(logit.score(X_test, y_test), 3),
(0.998, 0.867)
The coefficients of the model can be beautifully displayed.
def visualize_coefficients(classifier, feature_names, n_top_features=25):
# get coefficients with large absolute values
coef = classifier.coef_.ravel()
positive_coefficients = np.argsort(coef)[-n_top_features:]
negative_coefficients = np.argsort(coef)[:n_top_features]
interesting_coefficients = np.hstack([negative_coefficients, positive_coefficients])
# plot them
plt.figure(figsize=(15, 5))
colors = ["red" if c < 0 else "blue" for c in coef[interesting_coefficients]]
plt.bar(np.arange(2 * n_top_features), coef[interesting_coefficients], color=colors)
feature_names = np.array(feature_names)
plt.xticks(
np.arange(1, 1 + 2 * n_top_features),
feature_names[interesting_coefficients],
rotation=60,
ha="right",
);
def plot_grid_scores(grid, param_name):
plt.plot(
grid.param_grid[param_name],
grid.cv_results_["mean_train_score"],
color="green",
label="train",
)
plt.plot(
grid.param_grid[param_name],
grid.cv_results_["mean_test_score"],
color="red",
label="test",
)
plt.legend();
visualize_coefficients(logit, cv.get_feature_names_out());
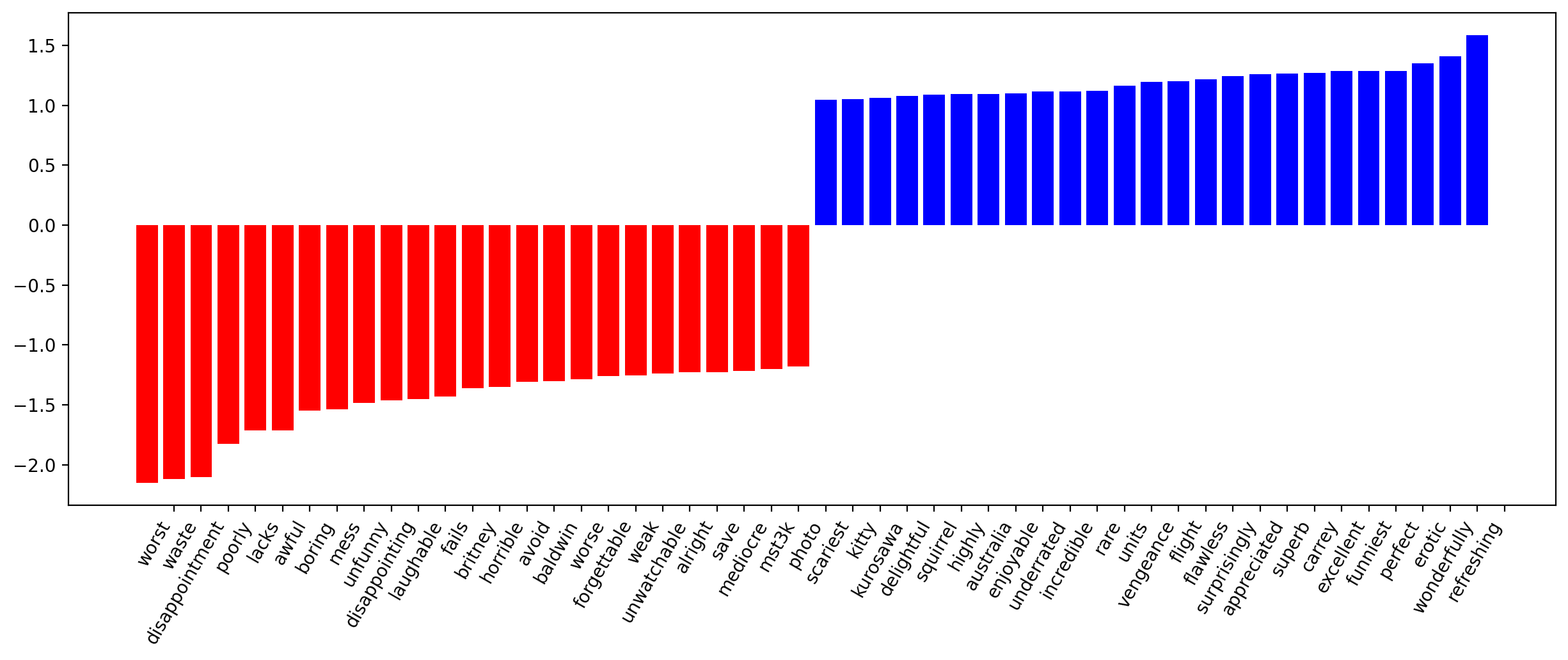
To make our model better, we can optimize the regularization coefficient for Logistic Regression. We’ll use sklearn.pipeline because CountVectorizer should only be applied to the training data (so as to not “peek” into the test set and not count word frequencies there). In this case, pipeline determines the correct sequence of actions: apply CountVectorizer, then train Logistic Regression.
%%time
from sklearn.pipeline import make_pipeline
text_pipe_logit = make_pipeline(
CountVectorizer(),
# for some reason n_jobs > 1 won't work
# with GridSearchCV's n_jobs > 1
LogisticRegression(solver="lbfgs", n_jobs=1, random_state=7, max_iter=500),
)
text_pipe_logit.fit(text_train, y_train)
print(text_pipe_logit.score(text_test, y_test))
0.86672
CPU times: user 7.4 s, sys: 124 ms, total: 7.53 s
Wall time: 7.54 s
%%time
from sklearn.model_selection import GridSearchCV
param_grid_logit = {"logisticregression__C": np.logspace(-5, 0, 6)}
grid_logit = GridSearchCV(
text_pipe_logit, param_grid_logit, return_train_score=True, cv=3, n_jobs=-1
)
grid_logit.fit(text_train, y_train)
CPU times: user 4.33 s, sys: 321 ms, total: 4.65 s
Wall time: 18.8 s
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('countvectorizer', CountVectorizer()),
('logisticregression',
LogisticRegression(max_iter=500,
n_jobs=1,
random_state=7))]),
n_jobs=-1,
param_grid={'logisticregression__C': array([1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00])},
return_train_score=True)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GridSearchCV(cv=3,
estimator=Pipeline(steps=[('countvectorizer', CountVectorizer()),
('logisticregression',
LogisticRegression(max_iter=500,
n_jobs=1,
random_state=7))]),
n_jobs=-1,
param_grid={'logisticregression__C': array([1.e-05, 1.e-04, 1.e-03, 1.e-02, 1.e-01, 1.e+00])},
return_train_score=True)Pipeline(steps=[('countvectorizer', CountVectorizer()),
('logisticregression',
LogisticRegression(C=np.float64(0.1), max_iter=500, n_jobs=1,
random_state=7))])CountVectorizer()
LogisticRegression(C=np.float64(0.1), max_iter=500, n_jobs=1, random_state=7)
Let’s print best \(C\) and cv-score using this hyperparameter:
grid_logit.best_params_, grid_logit.best_score_
({'logisticregression__C': np.float64(0.1)}, np.float64(0.8848399532333585))
plot_grid_scores(grid_logit, "logisticregression__C")
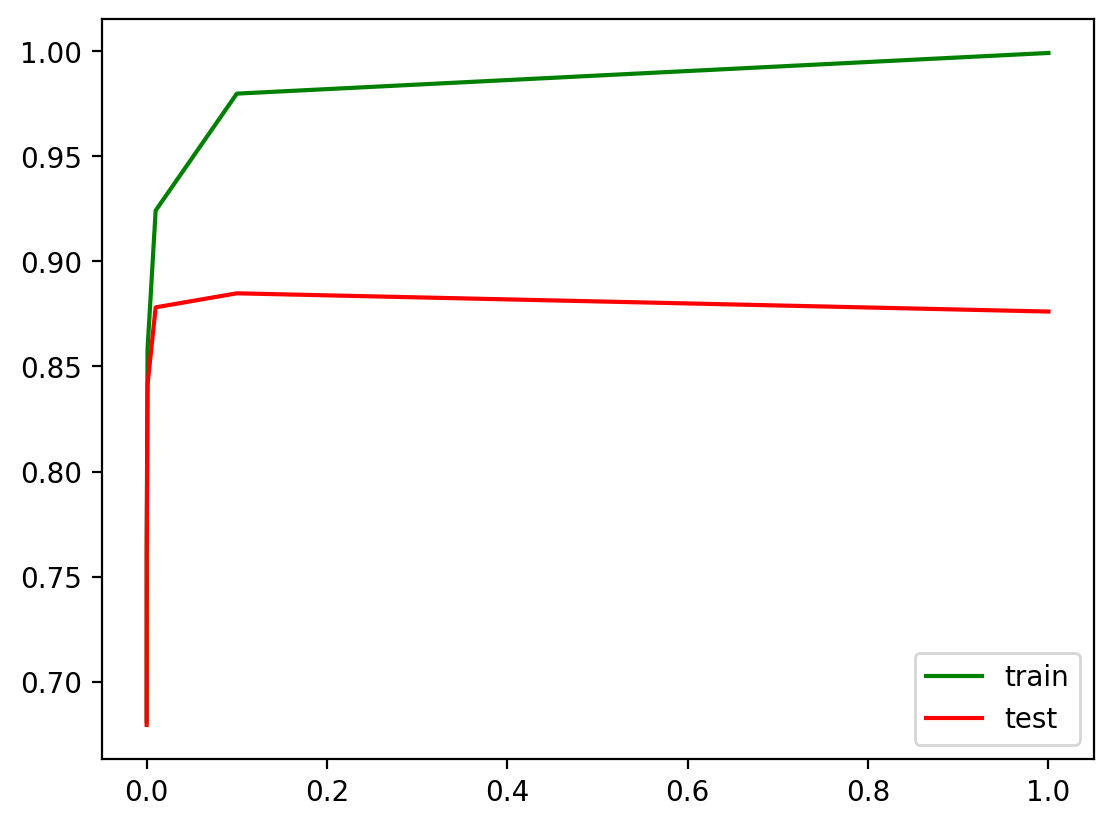
For the validation set:
grid_logit.score(text_test, y_test)
0.879
Now let’s do the same with random forest. We see that, with logistic regression, we achieve better accuracy with less effort.
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=200, n_jobs=-1, random_state=17)
%%time
forest.fit(X_train, y_train)
CPU times: user 53.3 s, sys: 291 ms, total: 53.6 s
Wall time: 4.95 s
RandomForestClassifier(n_estimators=200, n_jobs=-1, random_state=17)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(n_estimators=200, n_jobs=-1, random_state=17)
round(forest.score(X_test, y_test), 3)
0.855
3. The XOR Problem#
Let’s now consider an example where linear models are worse.
Linear classification methods still define a very simple separating surface - a hyperplane. The most famous toy example of where classes cannot be divided by a hyperplane (or line) with no errors is “the XOR problem”.
XOR is the “exclusive OR”, a Boolean function with the following truth table:
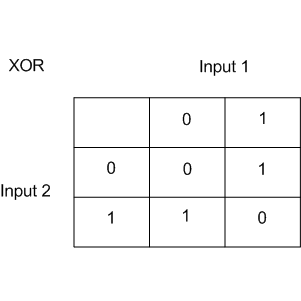
XOR is the name given to a simple binary classification problem in which the classes are presented as diagonally extended intersecting point clouds.
# creating dataset
rng = np.random.RandomState(0)
X = rng.randn(200, 2)
y = np.logical_xor(X[:, 0] > 0, X[:, 1] > 0)
plt.scatter(X[:, 0], X[:, 1], s=30, c=y, cmap=plt.cm.Paired);
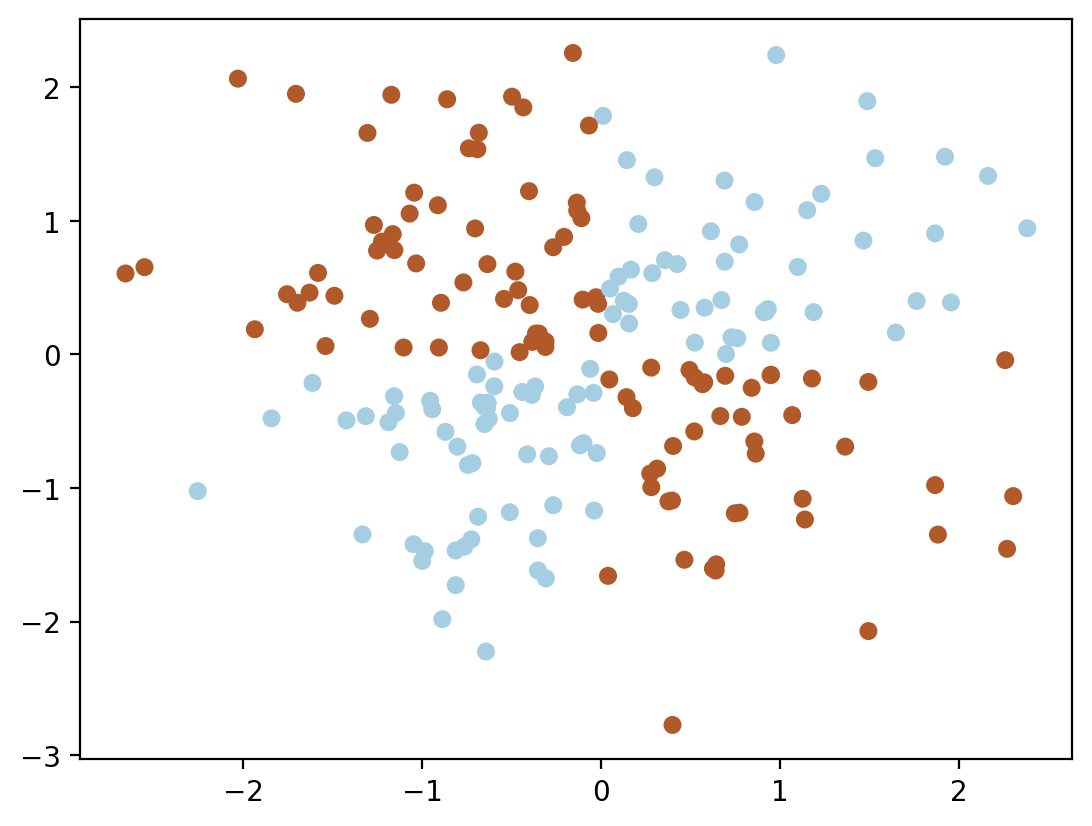
Obviously, one cannot draw a single straight line to separate one class from another without errors. Therefore, logistic regression performs poorly with this task.
def plot_boundary(clf, X, y, plot_title):
xx, yy = np.meshgrid(np.linspace(-3, 3, 50), np.linspace(-3, 3, 50))
clf.fit(X, y)
# plot the decision function for each datapoint on the grid
Z = clf.predict_proba(np.vstack((xx.ravel(), yy.ravel())).T)[:, 1]
Z = Z.reshape(xx.shape)
image = plt.imshow(
Z,
interpolation="nearest",
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
aspect="auto",
origin="lower",
cmap=plt.cm.PuOr_r,
)
contours = plt.contour(xx, yy, Z, levels=[0], linewidths=2)
plt.scatter(X[:, 0], X[:, 1], s=30, c=y, cmap=plt.cm.Paired)
plt.xticks(())
plt.yticks(())
plt.xlabel(r"$x_1$")
plt.ylabel(r"$x_2$")
plt.axis([-3, 3, -3, 3])
plt.colorbar(image)
plt.title(plot_title, fontsize=12);
plot_boundary(
LogisticRegression(solver="lbfgs", max_iter=500), X, y, "Logistic Regression, XOR problem"
)
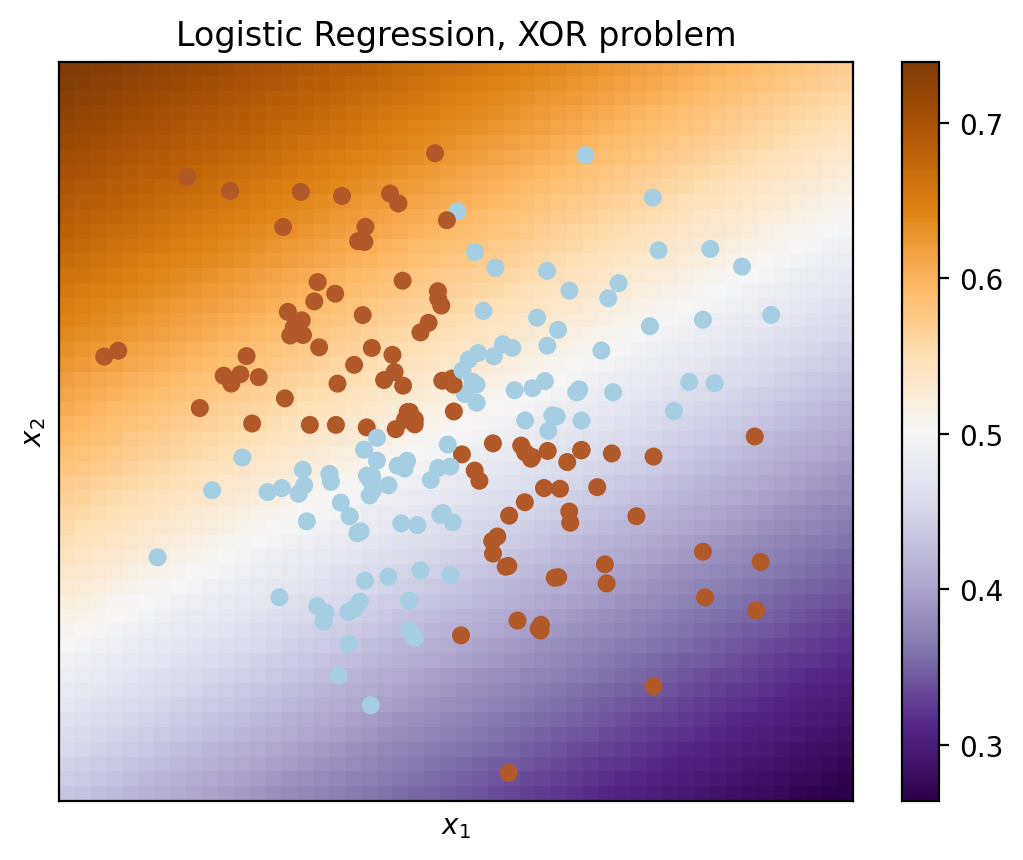
But if one were to give polynomial features as an input (here, up to 2 degrees), then the problem is solved.
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import PolynomialFeatures
logit_pipe = Pipeline(
[
("poly", PolynomialFeatures(degree=2)),
("logit", LogisticRegression(solver="lbfgs", max_iter=500)),
]
)
plot_boundary(logit_pipe, X, y, "Logistic Regression + quadratic features. XOR problem")
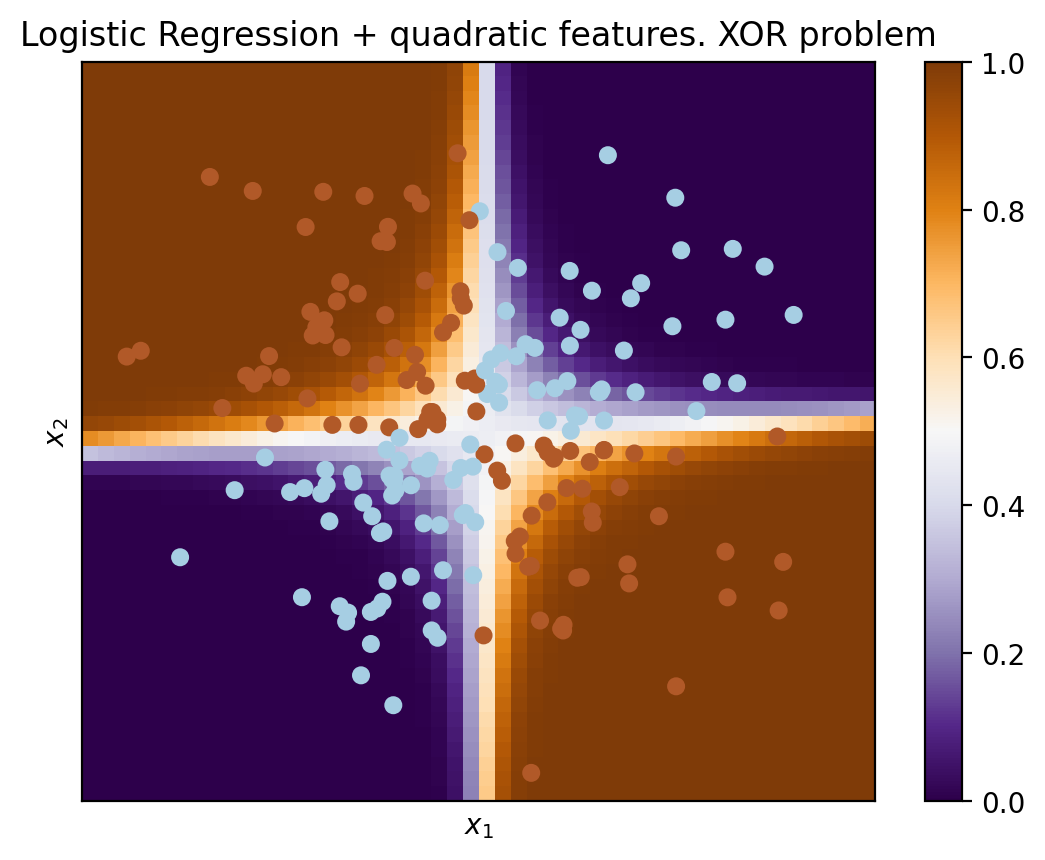
Here, logistic regression has still produced a hyperplane but in a 6-dimensional feature space \(1, x_1, x_2, x_1^2, x_1x_2\) and \(x_2^2\). When we project to the original feature space, \(x_1, x_2\), the boundary is nonlinear.
In practice, polynomial features do help, but it is computationally inefficient to build them explicitly. SVM with the kernel trick works much faster. In this approach, only the distance between the objects (defined by the kernel function) in a high dimensional space is computed, and there is no need to produce a combinatorially large number of features.
4. Useful resources#
Medium “story” based on this notebook
Main course site, course repo, and YouTube channel
Course materials as a Kaggle Dataset
If you read Russian: an article on Habr.com with ~ the same material. And a lecture on YouTube
A nice and concise overview of linear models is given in the book “Deep Learning” (I. Goodfellow, Y. Bengio, and A. Courville).
Linear models are covered practically in every ML book. We recommend “Pattern Recognition and Machine Learning” (C. Bishop) and “Machine Learning: A Probabilistic Perspective” (K. Murphy).
If you prefer a thorough overview of linear models from a statistician’s viewpoint, then look at “The elements of statistical learning” (T. Hastie, R. Tibshirani, and J. Friedman).
The book “Machine Learning in Action” (P. Harrington) will walk you through implementations of classic ML algorithms in pure Python.
Scikit-learn library. These guys work hard on writing really clear documentation.
Scipy 2017 scikit-learn tutorial by Alex Gramfort and Andreas Mueller.
One more ML course with very good materials.
Implementations of many ML algorithms. Search for linear regression and logistic regression.