Bonus Assignment 3. Decision trees#
You can purchase a Bonus Assignments pack with the best non-demo versions of mlcourse.ai assignments. Select the “Bonus Assignments” tier on Patreon or a similar tier on Boosty (rus).

![]()
Details of the deal
mlcourse.ai is still in self-paced mode but we offer you Bonus Assignments with solutions for a contribution of $17/month. The idea is that you pay for ~1-5 months while studying the course materials, but a single contribution is still fine and opens your access to the bonus pack.
Note: the first payment is charged at the moment of joining the Tier Patreon, and the next payment is charged on the 1st day of the next month, thus it’s better to purchase the pack in the 1st half of the month.
mlcourse.ai is never supposed to go fully monetized (it’s created in the wonderful open ODS.ai community and will remain open and free) but it’d help to cover some operational costs, and Yury also put in quite some effort into assembling all the best assignments into one pack. Please note that unlike the rest of the course content, Bonus Assignments are copyrighted. Informally, Yury’s fine if you share the pack with 2-3 friends but public sharing of the Bonus Assignments pack is prohibited.
In this assignment, we’ll go through the math and code behind decision trees applied to the regression problem, some toy examples will help with that. It is good to understand this because the regression tree is the key component of the gradient boosting algorithm which we cover in the end of the course.
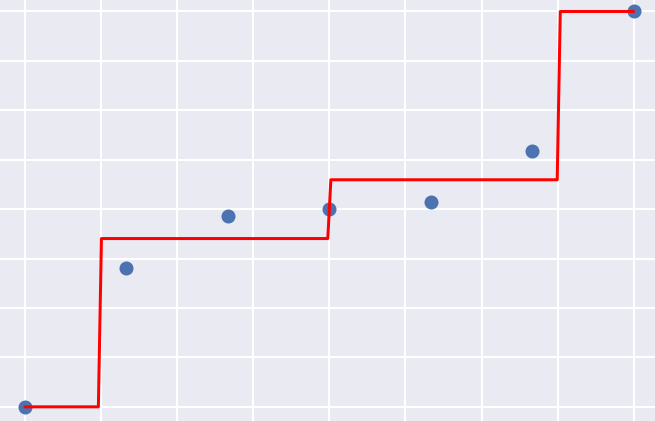
Left: Building a regression tree, step 1. Right: Building a regression tree; step 3
Further, we apply classification decision trees to cardiovascular disease data.
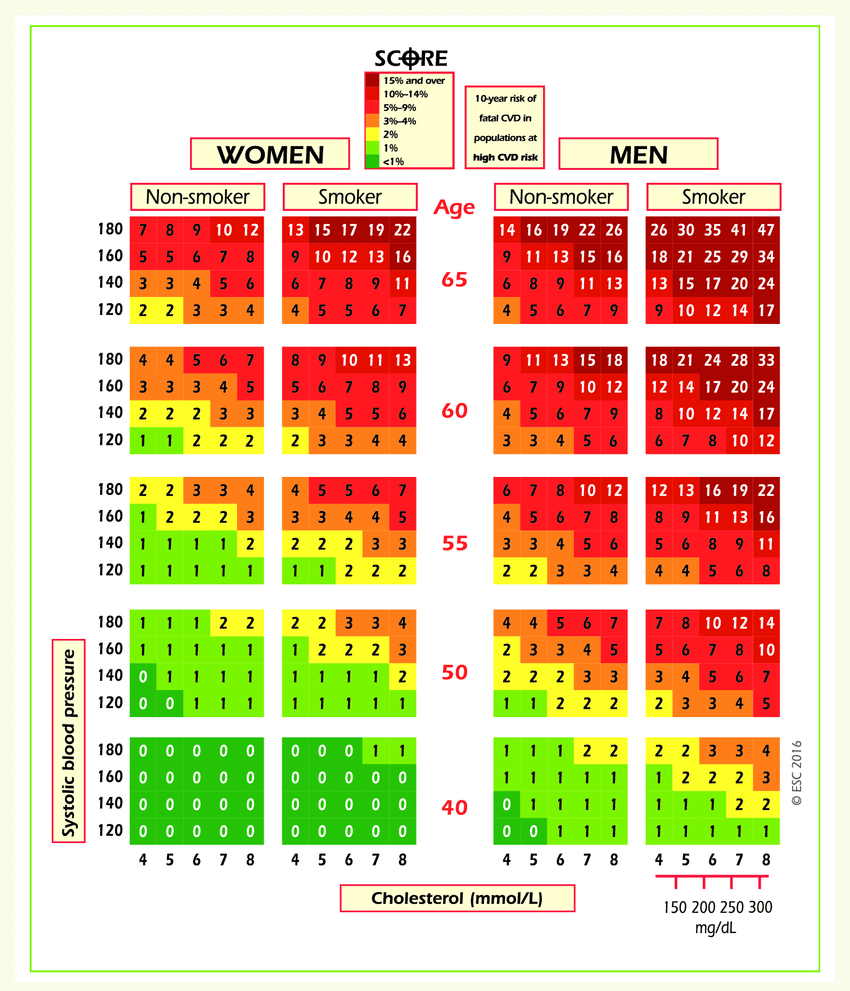
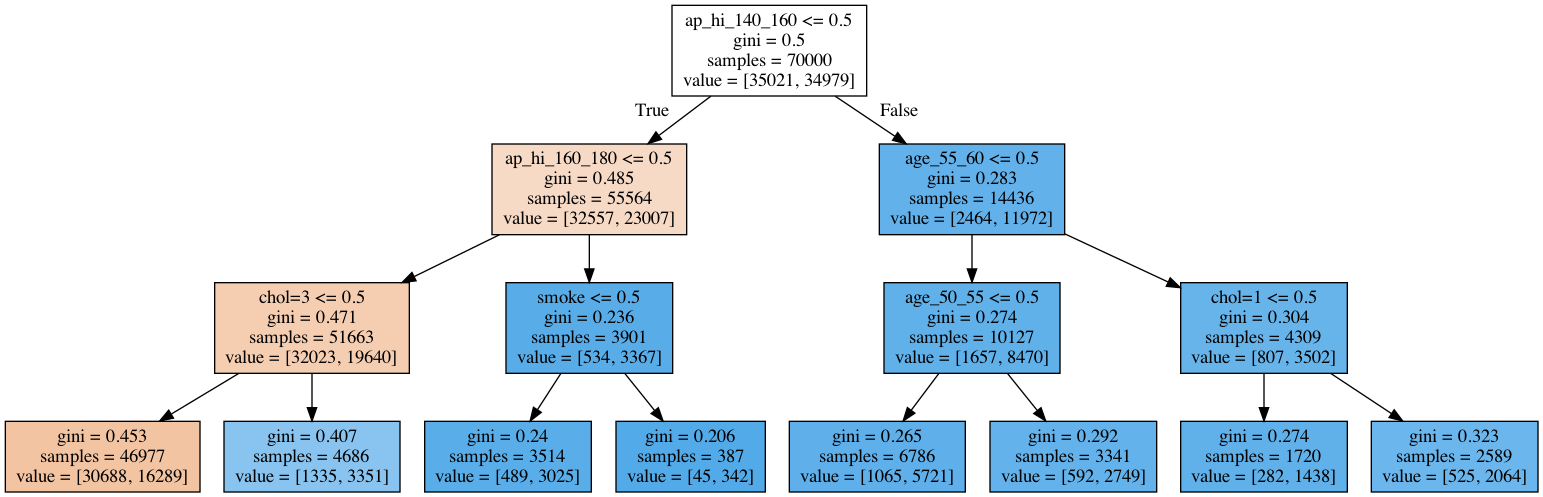
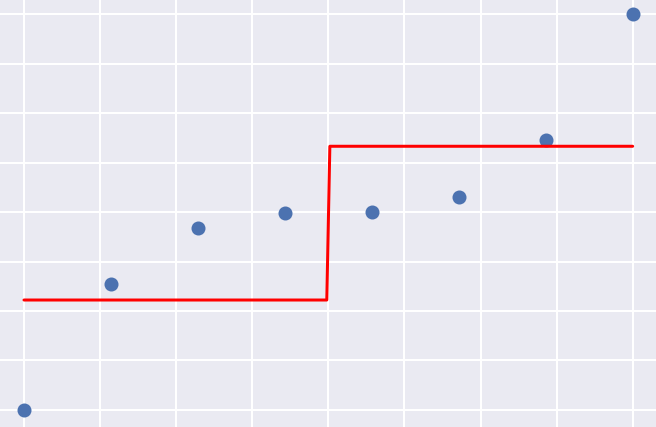
Left: Risk of fatal cardiovascular disease. Right: A decision tree fit to cardiovascular disease data.
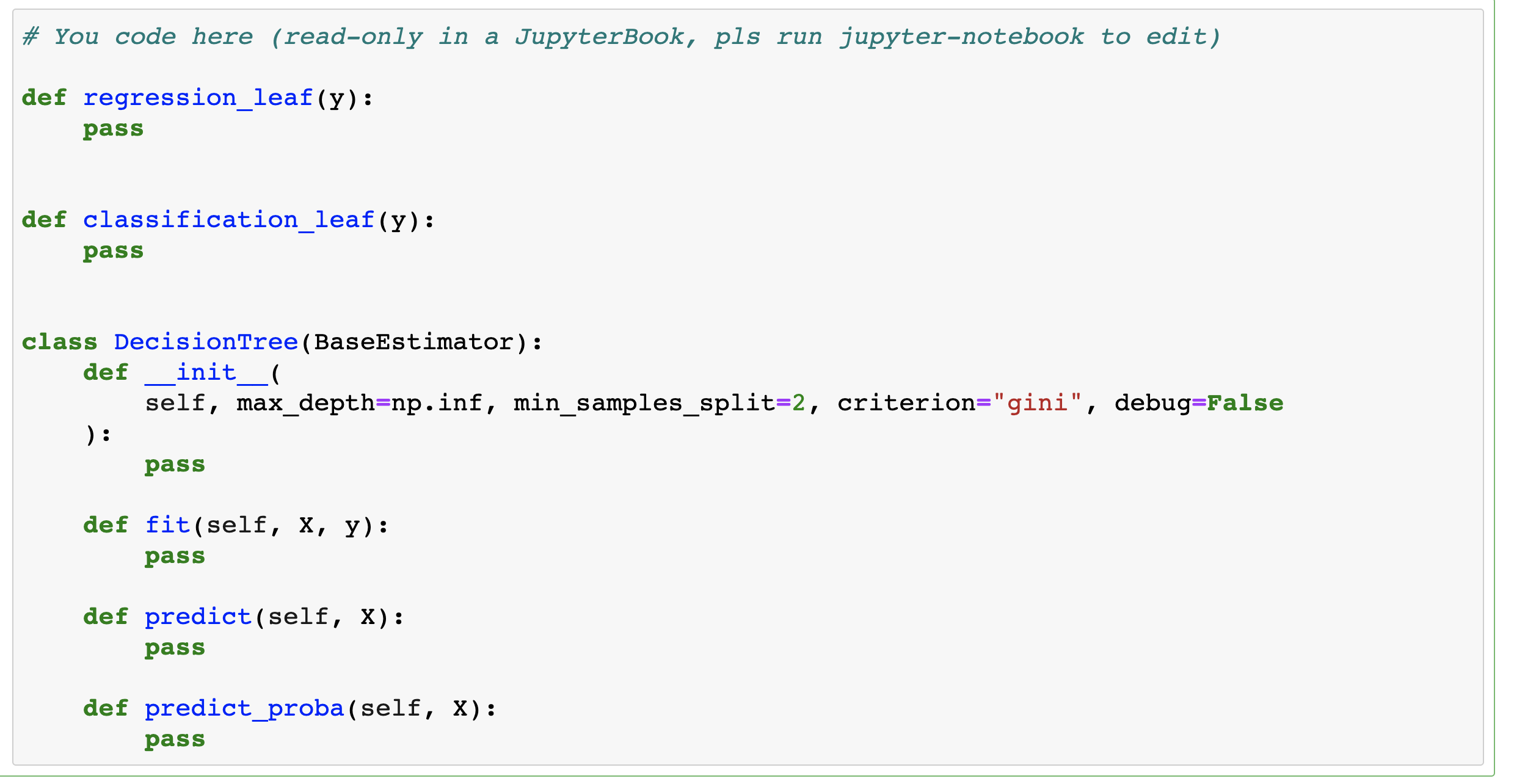
In one more bonus assignment, a more challenging one, you’ll be guided through an implementation of a decision tree from scratch. You’ll be given a template for a general DecisionTree class that will work both for classification and regression problems, and then you’ll be testing the implementation with a couple of toy- and actual classification and regression tasks.